First of all, congratulations on choosing Linux, you may be on the road to Linux. Before you leave, let me take a look at everything about Linux and Linux operation and maintenance.
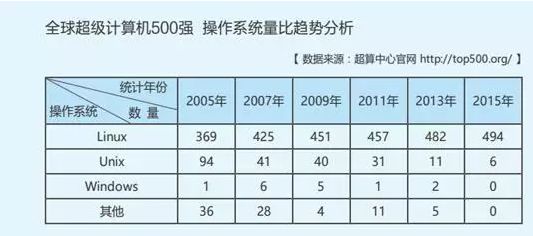
Because of its high efficiency, easy cutting, and wide application, Linux has become the main operating system of today's high-end servers, and is in an irreplaceable position. Linux can be installed on a variety of computer hardware devices, such as mobile phones, tablets, routers, video game consoles, desktop computers, mainframes, and supercomputers. With the rapid development of Linux in the Chinese market, the gap in domestic Linux talent has become increasingly prominent. Linux talent recruitment has also become one of the most popular recruits.
First of all, linux is a very, very big concept. It is impossible to think through it all. Ideally, if you understand Linux, you can do all the work. Individuals are more inclined to say what kind of work they want to do and what part of linux they need to learn.
According to personal experience, what are the common areas of Linux and what work is corresponding to it. 1) Linux application. This part is strictly not linux, just running applications on linux, such as web, network, IT, etc., including system development, background development, server performance optimization, operation and maintenance, etc.
2) Linux customization. This part involves more linux version of the user package, the kernel will have some involved, mainly various commercial linux custom, services and so on. For example, redhat and the like, many of them are foreign companies, and most of them domestically support on-site support.
3) Linux kernel development. This part is mainly the development of linux kernel driver. Almost all programming work. Mainly chip companies, and product development companies that use chips. The former is intel, marvell, and the latter is like ZTE Huawei.
4) android derivatives. Because android includes the linux kernel that is slowly used by tizen, so the reason is the same as 3. So mobile chip companies and mobile phone development companies are also employers of Linux developers. Such as Qualcomm, TI, etc.;
First, the main work content of Linux operation and maintenance
Linux operation and maintenance As the job with the largest number of jobs and the highest salary, this paper focuses on the occupation of Linux operation and maintenance. The content of this article is jointly written by Marco Ge Education and enthusiasts who specialize in Linux operation and maintenance learning and career development.
Internet Linux operation and maintenance work, service-oriented, stable, secure, and efficient three basic points to ensure that the company's Internet business can provide users with high-quality services 7 × 24 hours. The operational responsibilities cover the life cycle of the product from design to release, operation and maintenance, change and upgrade, and downline.
The responsibility of operation and maintenance in the whole life cycle of the product is important and extensive, but the duties of the operation and maintenance engineers are not limited to this part of the work, but also need to summarize the problems encountered in the work, extract relevant technical directions, research and development related tools and platforms. To support/optimize the development of the business and improve the efficiency of operation and maintenance, the related technical work mainly includes:
Service monitoring technology: including the development and application of monitoring platform, service monitoring accuracy, real-time, comprehensive protection
Service fault management: including the fault plan design of the service, the automatic execution of the plan, the summary of the fault and feedback to the design level of the product/system for optimization to improve the stability of the product.
Service capacity management: measuring the capacity of services, planning the construction of the computer room, expanding, and relocating
Service performance optimization: Improve service performance and response speed and improve user experience from all directions, including network optimization, operating system optimization, application optimization, and client optimization.
Service global traffic scheduling: traffic accessing services, allocating traffic in each room according to capacity and service status
Service task scheduling: scheduling trigger and status monitoring of various scheduled/non-timed tasks of the service
Service security: including access security, anti-attack, permission control, etc.
Data transmission technology: including R&D and application of various transmission technologies such as p2p, and solving problems such as long-distance big data transmission.
Service auto-release deployment: development of deployment platform/tools, and use of platforms/tools for secure and efficient publishing services
Service cluster management: server management including services, large-scale cluster management, etc.
Service cost optimization: minimize the resources used by the service operation and reduce the service operation cost
Database Management (DBA): Makes database services more stable, efficient, and easier to manage by designing, developing, and managing high-performance database clusters.
Platform-based development: development management of platforms such as docker, and service access technology
Development optimization and access of distributed storage platforms
Etc. All work related to service quality, efficiency, cost, safety, etc., and the technologies, components, tools, and platforms involved are in the technical scope of operation and maintenance. Doing a good job in each technical direction, completing the corresponding components, tools, and platform development can play a positive role in fulfilling the operational and responsibilities, and play a key role in the development of the business.
Second, Linux operation and maintenance work classification
The operation direction of operation and maintenance is relatively large. With the continuous development of business scale, the more mature Internet companies, the more detailed the operation and maintenance posts will be divided. At present, many large-scale Internet companies only have system operation and maintenance during the initial period. With the requirements of model and service quality, they have gradually carried out work breakdown. Under normal circumstances, the operation classification of the operation and maintenance team (see Figure 1-1) and responsibilities are as follows.

Figure 1-1 Classification of the operation and maintenance team
2.1-Application Operation and Maintenance (SRE): The application operation and maintenance is responsible for online service changes, service status monitoring, service disaster recovery, and data backup. The service is routinely checked and the emergency response is handled. The duties are as follows: Review, service management, resource management, routine inspection, plan management, data backup.
2.2-System Operation and Maintenance (SYS): Responsible for the construction of IDC, network, CDN and basic services (LVS, NTP, DNS); responsible for asset management, server selection, delivery and maintenance, job responsibilities are as follows: IDC data center construction, network Construction, LVS load balancing and SNAT construction, CDN planning and construction, server selection, delivery and maintenance, kernel selection and OS related maintenance, asset management, and infrastructure services.
2.3-Database operation and maintenance (DBA): Database operation and maintenance is responsible for data storage scheme design, database table design, index design and SQL optimization, and changes, monitoring, backup, and high-availability design of the database. The detailed work contents are as follows: Review, capacity planning, data backup and disaster recovery, database monitoring, database security, database high availability and performance optimization, automation system construction, operation and maintenance research and development, operation and maintenance platform, monitoring system, automated deployment system.
2.4-Operation and Maintenance Security (SEC): Operation and maintenance security is responsible for security hardening of network, system and service, conducting regular security scanning, penetration testing, security tool and system development, and security incident emergency response. The work contents are as follows: Safety system establishment, safety training, risk assessment, safety construction, safety compliance, and emergency response.
Third, Linux operation and maintenance daily use software and skills
Operation and maintenance platforms and tools used by operation and maintenance engineers include:
Web server: apache, tomcat, nginx, lighttpd
Monitoring: nagios, ganglia, cacti, zabbix
Automatic deployment: ansible, sshpt, salt
Configuration management: puppet, cfengine
Load balancing: lvs, haproxy, nginx
Transfer tool: scribe, flume
Backup tool: rsync, wget
Database: mysql, oracle, sqlserver
Distributed platform: hdfs, mapreduce, spark, storm, hive
Distributed database: hbase, cassandra, redis, MongoDB
Container: lxc, docker
Virtualization: openstack, xen, kvm
Security: kerberos, selinux, acl, iptables
Problem tracking: netstat, top, tcpdump, last
Operation and maintenance is based on technology and provides higher quality services through technical support products. The responsibilities of the operation and maintenance work and the position in the business determine that the operation and maintenance engineers need to have more extensive knowledge and in-depth technical capabilities:
Solid computer basic knowledge, including computer system architecture, operating system, network technology, etc.;
General applications need to understand the operating system, network, security, storage, CDN, DB, etc., know the relevant principles;
The programming ability, from the development of operation and maintenance tools to the development of large-scale operation and maintenance systems/platforms, requires good programming skills;
Data analysis ability: It can organize and analyze various data of system operation, find problems and find solutions;
Rich system knowledge, including system tools, typical system architecture, common platform selection, etc.
The ability to leverage tools and platforms;
Fourth, the development process of Linux operation and maintenance work
The early operation and maintenance team was mainly engaged in data center construction, basic network construction, server procurement, and server installation and delivery in the case of fewer personnel. Almost rarely involve changes, monitoring, management, etc. of online services. At this time, the operation and maintenance team is more of an infrastructure role, providing a simple and usable network environment and system environment.
As business products mature, there are higher requirements for service quality. At this time, the operation and maintenance team will also undertake some server monitoring work, and will be responsible for LVS, Nginx and other 4/7 layer operation and maintenance work unrelated to business logic. At this time, the service changes are more manual, or some simple batch scripts appear. The focus of monitoring is more on the status of the server and resource usage, monitoring the status of the service application is almost rare, monitoring more use of various open source systems such as Nagios, Cacti and so on.
Due to the continuous increase in business scale and complexity, the operation and maintenance team will gradually be divided into two parts: application operation and maintenance and system operation and maintenance. Application operation and maintenance began to take over the online business, and gradually carried out service monitoring, data backup and service change. With the deepening of the service, the application operation and maintenance engineer has the ability to start some simple optimization of the service. At the same time, in order to deal with a large number of service changes every day, we also began to write a variety of operation and maintenance tools, for a number of specific services can be easily changed in batches. As the scale of the business increases, the infrastructure has more and more faults due to insufficient capacity planning or weak ability to withstand risks, forcing the operation and maintenance personnel to start putting more energy into the disaster recovery and plan management of multiple data centers. In the direction.
After the business scale reaches a certain level, the open source monitoring system can not meet the business needs in terms of performance and function; a large number of service changes, complex service relationships, and previous methods of manual recording and tool change, regardless of efficiency or accuracy. Can not meet the business needs; there are various events in the security aspect, forcing us to invest more energy in security defense. Gradually, the operation and maintenance team formed the five major job classifications mentioned before, and each category required specialized talents. At this time, the system operation and maintenance is more focused on infrastructure construction and operation and maintenance, providing a stable and efficient network environment, and delivering resources such as servers to application operation and maintenance engineers. Application operation and maintenance is more focused on service operation status and efficiency. Database operation and maintenance is a refinement of application operation and maintenance work, focusing on automation, performance optimization and security defense in the database field. Operation and maintenance R&D and operation and maintenance security provide various platforms and tools to further enhance the work efficiency of operation and maintenance engineers, so that business services run more stably, efficiently and safely.
We divide the operation and maintenance development process into four phases, as shown in Figure 1-2.
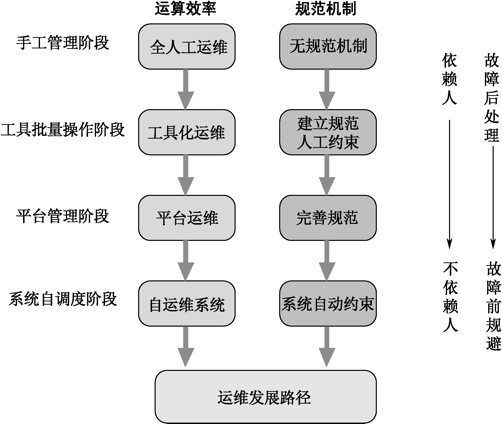
Figure 1-2 Operation and maintenance development process
Manual management phase: The service traffic is not large, the number of servers is relatively small, and the system complexity is not high. For daily business management operations, everyone is more logged in to the server for manual operation. They belong to their own battles. Everyone has their own operation mode. They lack the necessary operating standards and process mechanisms. For example, the business directory environment is Various.
Tool batch operation phase: With the increase of server scale and system complexity, the full manual operation mode can not meet the rapid development needs of the business. As a result, O&M personnel are beginning to use batch-based operating tools, and different scripting programs appear for different types of operations. But each team has its own tools that need to be adjusted each time the operational requirements change. This is mainly due to insufficient specifications for the environment and operation, resulting in weak programmability. At this point, although the efficiency has increased a little, but soon encountered a bottleneck. The quality of the operation is not much improved, and even larger problems may arise due to batch execution. We started to build a large number of process specifications, such as the review mechanism, first on the line to observe a server for 10 minutes and then continue the next operation, at least 20 minutes after an upgrade. These are mainly relied on people to supervise and execute, but in the actual process, execution is often not in place, but it reduces work efficiency.
Platform management stage: At this stage, we have higher requirements for operation and maintenance efficiency and misoperation rate. We decided to start the operation and maintenance platform, and carry the standards and processes through the platform to liberate people and improve quality. At this time, the change action of the service is abstracted, and a unified standard such as the operation method, the service directory environment, and the service operation mode is formed. For example, the start/stop interface of the program must include start, stop, and overload. The operating process is constrained by the platform, as observed above for one server on the line for 10 minutes. The pause checkpoint is forcibly set in the platform. After the operation of the first server is completed, the operation and maintenance personnel are required to fill in the corresponding check items, and then the subsequent deployment actions can be continued.
The system self-scheduling phase: the larger number of services, more complex service associations, and the integration of various operation and maintenance platforms. The original way of converting batch operations into platform operations is no longer suitable, and it is necessary to make higher service changes. The abstraction of a layer. Each server is abstracted into a container. The scheduling system dispatches and deploys the service to the appropriate server according to the resource usage, and automatically completes linkage with various surrounding operation and maintenance systems, such as monitoring system, log system, backup system, etc. . Through the self-scheduling system, dynamically scaling capacity based on service operation, it is possible to automate common service failures. The operation and maintenance personnel's work will also be advanced to the product design stage to assist the R&D personnel to transform the service so that they can access the self-scheduling system.
In the development process of the entire operation and maintenance, we hope that all the work will be automated, reduce the repetitive work of people, reduce the cost of knowledge transfer, make our operation and maintenance delivery more efficient and safer, and make the product run more stable. For the handling of faults, it is also hoped that the post-processing will become an early discovery, and the manual processing will become a system automatic disaster tolerance.
5. Frontier skills that must be captured in Linux operation and maintenance in 2018
This is the tip of the iceberg that is undergoing profound changes in the technological world. So what is the problem? How to transform as a traditional operation and maintenance?
Here are a few small suggestions: You need to learn these four parts:
Automated operation and maintenance (Ansible, Puppet, Saltstack, etc.)
Devops (Docker, K8s, Jenkins, Jira, etc.),
Cloud service technology (virtualization, OpenStack, AWS and Alibaba Cloud product service architecture, etc.)
With more than 15+ yrs rich MFG experience, you can definitely trust in and cooperate with.
Provide you with the supply of Personal Protective Equipment. to help you safely get back to your daily routine.
Our products include pulse Oximeter Finger, Forehead Thermometer, Automatic foam soap dispenser, etc.
Our strict quality control protocol thoroughly vets every aspect of production, storage, and shipments all the way way to our end customers.
infrared thermometers wholesale, forehead thermometer wholesale,wholesale thermometer suppliers
TOPNOTCH INTERNATIONAL GROUP LIMITED , https://www.mic11.com