On September 13th, the GPU Developers Conference was held in Beijing. Prof. Ma Huimin, chief scientist of Shanghai Science and Technology of Vertical Vision, gave a detailed explanation on the core issues of smart driving and visual perception.
Ma Huimin said that the 3D Image Lab laboratory in 2003 was listed at the Department of Electronic Engineering of Tsinghua University. They have always been concerned about the problem that identification technology has not overcome.
The three issues of small goals, strong occlusion, and high dynamics are their focus. Ma Huimin mainly introduced three models of machine learning in autopilot to solve the above three problems.
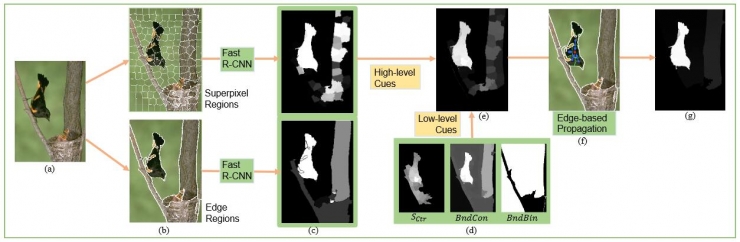 1. Significant Object Detection: Semantic Attention Cognitive Model
1. Significant Object Detection: Semantic Attention Cognitive Model
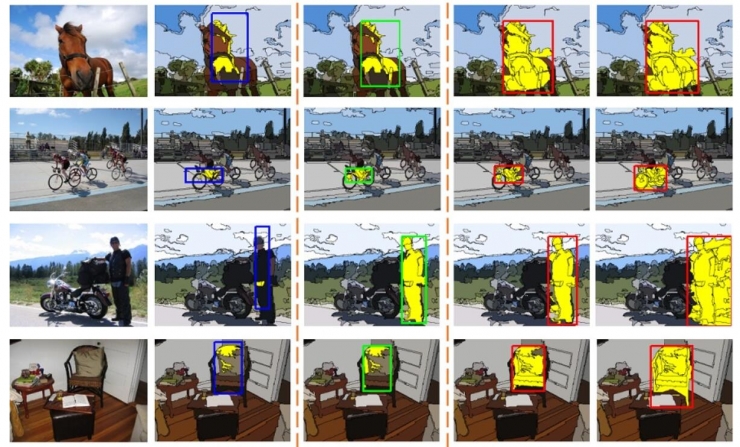 2. Parts and Cognitive Models: Resistance to Blocking
2. Parts and Cognitive Models: Resistance to Blocking
 3, 3D scene object recognition: adapt to complex environments
3, 3D scene object recognition: adapt to complex environments
First of all, to find significant objects in the detection of salient objects, to pave the way for the segmentation of images;
Secondly, the three aspects of components, structure, and environment are very important factors in image recognition. The characteristics of adding components can also resist the problem of occlusion;
Finally, to further interact with the environment, we use 3D information (stereo vision) as a semantic model of the object. Using three-dimensional road estimation and semantic features and then put it into a two-dimensional monocular camera, you will find that the test results are equivalent to the binocular camera. The reason is the correlation between their own a priori and the semantic up-and-down dimension.
In the three-dimensional a priori test, the height, width, and ratio of the car to the building can be determined, all within a certain range. From multiple modes, multi-tasks, and multiple perspectives, road inspections, multi-dimensional inspections from bird's-eye view to bird's-eye view, vehicle inspection, and positioning accuracy can all be improved by more than 6%.
They also compared stereo vision with lidar effects and hybrid sensor effects, but the addition of laser sensing to visual sensing has shown no significant improvement in road testing performance, and it is even worse than pure visual recognition with 2D 3D fusion.
In autopilot, lane detection, traffic sign detection, road signs, and overall path planning, etc., need to be implemented on the basis of embedded development to realize intelligent driving and visual perception in the operation of the unmanned vehicle algorithm, 3D Image Lab Lab uses the above three models to solve problems.

Power Adapter,Universal Power Adapter,Usb Power Adapter,67W Usb-C Power Adapter
Guang Er Zhong(Zhaoqing)Electronics Co., Ltd , https://www.geztransformer.com