
Recently, Beijing Institute of Technology, Technology Vision, and Peking University jointly published a paper called the Pyramid Attention Network for Semantic Segmentation. In this paper, four researchers proposed a Pyramid Attention Network (PAN) that uses image global context information to solve semantic segmentation problems.
Unlike most existing studies that use complex dilated convolutions and artificially designed decoder networks, the authors combine attentional mechanisms with spatial pyramids to extract accurate and dense features. And get pixel tags.
Specifically, they introduced a Feature Pyramid Attention module that imposes a spatial pyramidal attentional structure on top of the output and incorporates a global pooling strategy to learn better feature representations. In addition, the global context feature information obtained by the Global Attention Upsampling module in each decoder layer is used as a guide for low-level features to filter different types of positioning details.
The authors of the paper stated that their proposed method achieved the best performance on the PASCAL VOC 2012 data set. And without going through the pre-training process of the COCO dataset, their models achieved 84.0% mIoU in the PASCAL VOC 2012 and Cityscapes benchmarks.
Introduction
With the development of convolutional neural networks (CNN), the richness of hierarchical features and the availability of end-to-end training framework, significant progress has been made in the study of pixel-wise semantic segmentation. However, the existing research is still not ideal for the encoding of high dimensional feature representations, resulting in the loss of spatial resolution of contextual pixels in the original scene.
As shown in Figure 1, the Full Convolutional Network (FCN) lacks the ability to predict the small parts of the scene. In the figure, the handles of the first row of bicycles disappear and the sheep in the second row are mistaken for cattle. This presents a challenge to the semantic segmentation task. The first is that the existence of multi-scale targets will increase the difficulty of classification in semantic segmentation tasks. In order to solve this problem, PSPNet or DeepLab system proposes a spatial pyramid structure aimed at different grid scales or expansion rates (called space pyramid pooling, ASPP), and fusion of multi-scale feature information. In ASPP modules, expansion convolution is a sparse computation, which may lead to grid artifacts. The pyramid pooling module proposed in PSPNet may lose pixel-level positioning information. Inspired by Senet and Parsenet, we attempted to extract accurate pixel-level attention characteristics from the high-level features of CNN. Figure 1 shows the capabilities of the Feature Pyramid Attention (FPA) proposed by us. It can expand the range of receptive fields and effectively achieve the classification of small objects.

Figure 1: Visualization of VOC datasets
In the above figure, as we have seen, it is difficult for the FCN model to predict small goals and details. The handles of the bicycles in the first row were lost in the predictions, while the wrong animal category predictions appeared in the second row. Our Feature Pyramid Attention Module (FPA) and Global Attentive Upsampling (GAU) modules are designed to expand the target receptive field and effectively recover pixel positioning details.
Another problem is that high-level features are very effective in accurately classifying categories, but are weaker in reconstructing the class 2 prediction problems of the original resolution. Some U-type networks, such as SegNet, RefineNet, and Large Kernel Matters can use low-level information in complex decoder modules to help high-level features recover image details. However, these methods are time-consuming and inefficient. To solve this problem, we propose a method called Global Attention Upsample (GAU), which is an effective decoder module that can extract global context information of high-level features without excessive computational resources. As a guide to the weighted calculation of low-level features.
In general, our work mainly has the following three contributions:
1. We propose a feature pyramid attention module that can embed different scales of context feature information in FCN-based pixel prediction frameworks.
2. We have developed an efficient Global Modifier module, Global Attention Upsample, to handle the semantic segmentation of images.
3. Combining the feature pyramid attention module and global attention upsampling module, our Pyramid attention network achieved the best performance currently in the test benchmarks of VOC2012 and cityscapes.
â–ŒModeling method
Feature Pyramid Attention Module FPA
Based on the above observations, we have proposed the Feature Pyramid Attention Module (FPA), which can fuse the three different scales of pyramid features extracted from a U-shaped network (such as the feature pyramid network FPN). In order to better extract the context information of pyramid features at different scales, we use 3×3, 5×5, 7×7 convolution kernels in the pyramid structure respectively. Due to the low resolution of high-level feature maps, we use a larger kernel and do not impose a lot of computational burden. Subsequently, the pyramid structure gradually integrates feature information at different scales so that context features of adjacent scales can be more accurately combined. Then, after a 1×1 convolution process, the original features extracted by the CNN are multiplied pixel by pixel by the pyramidal attention features. In addition, we also introduced a global pooling branch to link the features of the output, which will further improve the performance of the FPA module. The overall module structure is shown in Figure 2 below. Thanks to the spatial pyramid structure, the FPA module can fuse different scales of contextual information while providing better pixel-level attention for high-level feature maps.

Figure 2: Feature Pyramid Attention Module Structure
In the figure above, (a) the spatial pyramid pool structure. (b) Feature Pyramid Attention Module. '4x4, 8x8, 16x16, 32x32' respectively represent different resolutions of the feature map. The dotted box represents the global pooled branch. The blue and red lines represent the downsampling and upsampling operators, respectively.
Global Attention Sampling Module GAU
The global attention upsampling module (GAU) proposed by us proposes the global contextual information as the guidance of the low-level features to select the positioning details of the categories. Specifically, we perform a 3×3 convolution operation on low-level features to reduce the number of channels in the CNN feature map. Global context information generated from high-level features is successively subjected to 1×1 convolution, batch normalization, and non-linearity operations, and then multiplied by low-level features. Finally, the high-level features are added to the weighted low-level features and a gradual upsampling process is performed. Our GAU module can not only adapt to feature mapping at different scales more effectively, but also provide guidance information for low-level feature mapping in a simple way. The schematic structure of the module is shown in Figure 3 below.
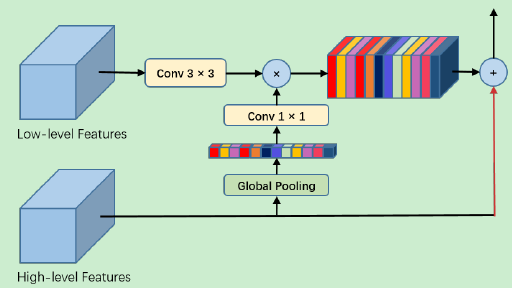
Figure 3: Global Attention Sampling Module
Pyramid attention network PAN
Combining the Feature Pyramid Attention Module (FPA) and the Global Attention Sampling Module (GAU), we propose the Pyramid Attention Network (PAN). The structure of the Pyramid Attention Network (PAN) is shown in Figure 4 below. We use the pre-trained ResNet-101 model on the ImageNet data set, supplemented by an extended convolutional strategy to extract feature maps. Specifically, we apply an expansive convolution with an expansion rate of 2 on the res5b module so that the size of the feature map output by ResNet is 1/16 of the original input image, which is consistent with the settings in the DeepLab v3+ model. As with the PSPNet and DUC models, we replaced the 7×7 convolution in the original ResNet-101 model with three 3×3 convolutional layers. In addition, we use the FPA module to collect intensive pixel-level attention information in ResNet's output. Combined with the global context information, the final prediction graph is generated after the GAU module.
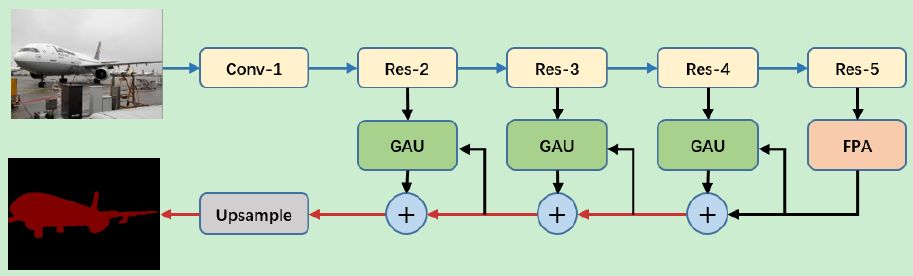
Figure 4: Pyramid Attention Network Structure
In the above figure, we use the ResNet-101 model to extract dense features. Then, we performed the FPA module and the GAU module respectively to perform accurate pixel prediction and obtain the details of the target location. The blue and red lines represent the downsampling and upsampling operators, respectively.
We regard the FPA module as a central module between the encoder and decoder structure. Even without a global attention to the upsampling module, the FPA module is able to perform sufficiently accurate pixel-level prediction and classification. After implementing the FPA module, we view the GAU module as a fast and efficient decoder structure that uses high-level features to guide low-level information and combines them.
â–ŒExperimental results
We evaluated our method separately on the PASCAL VOC2012 and the cityscapes dataset.
Ablation Experiments
FPA module
We performed Ablation Experiments analysis on the pooling type, pyramid structure, convolution kernel size, and global pooling settings. The results are as follows: where AVE represents the average pooling strategy, MAX represents the maximum pooling, and C333 represents all uses of 3× 3 for the convolution kernel, C357 indicates that the convolution kernels used are 3x3, 5x5, and 7x7 respectively, GP stands for global pooling branch, and SE stands for use of the SENet attention module.
Pooling type: In this work, we found that AVE's performance is better than MAX: for a 3×3 convolution kernel setting, the AVE performance can reach 77.54%, which is better than the 77.13% achieved by MAX.
Pyramid structure: Our model can achieve 72.60% mIoU on validation set. In addition, when we use C333 and AVE, the performance of the model can be increased from 72.6% to 77.54%. We also use the SENet attention module to replace the pyramid structure and further evaluate the performance of both. The experimental results are shown in Table 1 below. Compared with the SENet attention module, the C333 and AVE settings can improve the performance by nearly 1.8%.
Convolution kernel size: For the average pooled pyramid structure, we use C357 instead of the C333 convolution kernel. The resolution of the feature map in the pyramid structure is 16×16, 8×8, and 4×4. Experimental results show that the model performance can be increased from 77.54% to 78.19%.
Global Pooling: We further added global pooling branches in the pyramid structure to improve model performance. Experimental results show that the model can obtain 78.37 mIoU and 95.03% Pixel Acc under optimal settings.
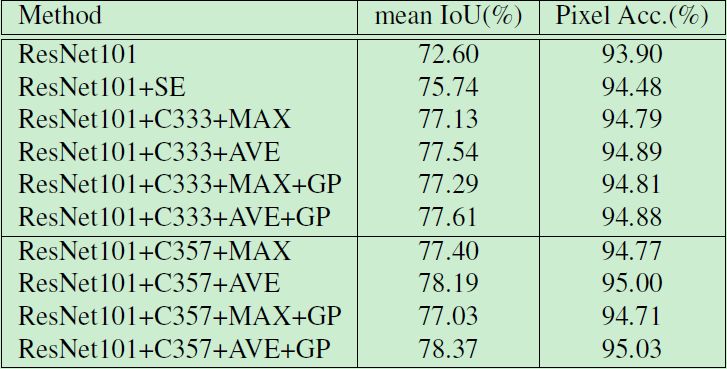
Table 1: Performance of FPA Modules in Different Settings
GAU module
First, we evaluate the ResNet101+GAU model, and then we combine the FPA and GAU modules and evaluate our model in the VOC 2012 validation set. We evaluated the model under three different decoder settings: (1) Only the low-level features of the jump connection were used and there was no global context attention branch. (2) Use 1×1 convolution to reduce the number of low-level feature channels in the GAU module. (3) Use 3×3 convolution instead of 1×1 convolution to reduce the number of channels. The experimental results are shown in Table 2.

Table 2: Model performance under different decoder settings
In addition, we also compared the ResNet101+GAU model, the Global Convolution Network, and the Discriminate Feature Network. The experimental results are shown in Table 3.

Table 3: Comparison of our model with other models
PASVAL VOC 2012 dataset
Combining the best settings for the FPA module and the GAU module, we evaluated our Pyramid Attention Network (PAN) on the PASVAL VOC 2012 data set. The experimental results are shown in Tables 4 and 5. As can be seen, PAN achieved 84.0% mIoU, surpassing all existing methods.
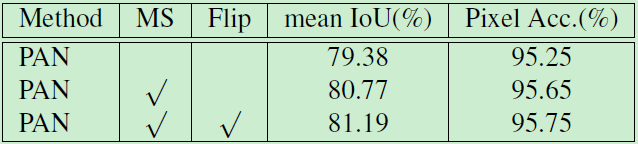
Table 4: Model Performance on VOC 2012 Datasets
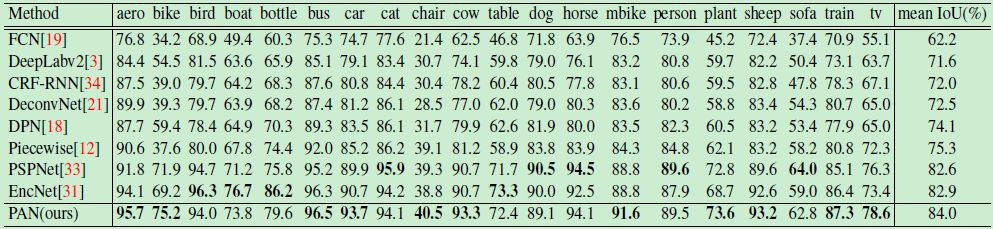
Table 5: Single category results on the PASVAL VOC 2012 test set
Cityscapes dataset
The Cityscapes dataset contains 30 categories of which 19 are used for our model training and assessment. The entire dataset contains 5000 images with fine-grained annotation and 19998 images with coarse-grained annotation. Specifically, we divided fine-grained images into training sets, validation sets, and test sets, with 2979, 500, and 1525 images, respectively. During training, we did not use datasets with coarse-grained annotation. The image size used was 768×768. Similarly, we use ResNet101 as the basic model. The experimental results are listed in Table 6.
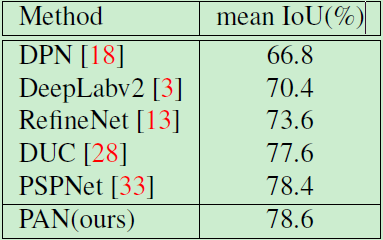
Table 6: Model Performance on Cityscapes Test Set
Conclusion
In this paper, we propose a Pyramid attention network for processing image semantic segmentation problems. We designed the Feature Pyramid Attention Module (FPA) and the Global Attention Sampling Module (GAU). The FPA module can provide pixel-level attention information and extend the scope of the receptive field through a pyramid structure. The GAU module can use high-level feature maps to guide the positioning of low-level feature recovery image pixels. The experimental results show that the proposed method achieves the best performance in PASCAL VOC 2012 semantic segmentation task.
1. The blades of an axial fan push air to flow in the same direction as the shaft. The impeller of an axial fan is similar to the propeller. When it works, most of the airflow is parallel to the shaft, in other words along the axis. When the inlet airflow is free air with zero static pressure, the axial flow fan has the lowest power consumption. When operating, the power consumption will increase as the airflow back pressure rises. Axial fans are usually installed in cabinets of electrical equipment, and sometimes integrated on motors. Because of their compact structure, they can save a lot of space and are easy to install, so they are widely used.
Its characteristics: high flow rate, medium wind pressure
2. Centrifugal fan
When the centrifugal fan works, the blades push air to flow in a direction perpendicular to the shaft (ie, radial), the air intake is along the axis direction, and the air outlet is perpendicular to the axis direction. In most cases, the cooling effect can be achieved by using an axial fan. However, sometimes if the airflow needs to be rotated by 90 degrees or when a larger wind pressure is required, a centrifugal fan must be used. Strictly speaking, fans are also centrifugal fans.
Its characteristics: limited flow rate, high wind pressure
3. Mixed flow fan
Mixed flow fans are also called diagonal flow fans. At first glance, mixed flow fans are no different from axial flow fans. In fact, the air intake of mixed flow fans is along the axis, but the air outlet is along the diagonal direction of the axis and the vertical axis. Because the blades and outer cover of this fan are called conical, the wind pressure is higher. Under the same size and other comparable performance, the centrifugal fan has lower noise than the axial fan.
Its characteristics: high flow rate and relatively high wind pressure
4-flow fan
Tubular wind flow can produce a large area of wind flow, which is usually used to cool large surfaces of equipment. The inlet and outlet of this fan are perpendicular to the axis (see Figure 1). The cross flow fan uses a relatively long barrel-shaped fan impeller to work. The diameter of the barrel-shaped fan blade is relatively large. Because of the large diameter, it can use a relatively low speed on the basis of ensuring the overall air circulation. , Reduce the noise caused by high-speed operation.
Its characteristics: low flow rate, low wind pressure
Axial Fan,Axial Flow Fan,Tube Axial Fan,Axial Exhaust Fan
Original Electronics Technology (Suzhou) Co., Ltd. , https://www.original-te.com