I was shocked when I first came into contact with the Long and Short Term Memory Neural Network (LSTM).
It turns out that LSTM is an extension of the neural network and is very simple. Deep learning has achieved many amazing results in the past few years, all of which are closely related to LSTM. Therefore, in this article I will introduce LSTM to you in the most intuitive way possible – so that you can explore it yourself in the future.
First, please see the picture below:
Is LSTM very beautiful?
Note: If you are familiar with neural networks and LSTM, skip to the middle of this article - the first half is equivalent to the introductory tutorial.
Neural Networks
Suppose we take a series of images from a movie, and we want to mark each image to make it an event (is it a fight? Are the actors talking? Are the actors eating?)
what should we do?
One of the methods is to construct a single image classifier that processes each image separately, ignoring the continuous attributes of the image. For example, provide enough images and labels:
Our algorithm may first need to learn to detect low-level graphics such as shapes and edges.
In the case of more data, the algorithm may learn to combine these graphics with more complex forms, such as a human face (a triangle above the elliptical thing, two circles on the triangle) or a cat .
If the amount of data is further increased, the algorithm may learn to map these advanced patterns to the activity itself (the scene containing the mouth, steak and fork may be eating)
This is a deep neural network: inputting an image and then outputting the corresponding event - this is the same as we can detect the various characteristics of the puppies by learning nothing about dogs. After observing enough Corgis, we found that they have some common features, such as fluffy hips and short limbs; next, we continue to learn more advanced features, such as excretion behavior, etc.) - in these two Between steps, the algorithm learns to describe the image by vector representation of the hidden layer.
Mathematical expression
Although you may already be familiar with basic neural networks, here is a quick review:
The single hidden layer neural network takes the vector x as input and we can think of it as a set of neurons.
The algorithm connects each input neuron to an implicit layer of neurons through a set of learned weights.
The jth hidden layer neuron output is 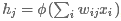 , where φφ is the activation function.
, where φφ is the activation function.
The hidden layer is fully connected to the output layer, and the output of the jth output neuron is 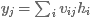 If you need to know the probability, we can use the softmax function to convert the output layer.
If you need to know the probability, we can use the softmax function to convert the output layer.
Expressed in matrix symbols as:
h=φ(Wx)h=φ(Wx)
y=Vhy=Vh
among them
Matchx is the input vector
W is the weight matrix connecting the input layer and the hidden layer
V is the weight matrix connecting the hidden layer and the output layer
The activation function of φ is usually the sigmoid function σ(x), which shrinks the number to (0, 1); the hyperbolic tangent tanh(x), which shrinks the number to (- 1, 1) In the interval, correct the linear unit ReLU(x)=max(0,x).
The figure below is a graphical view:
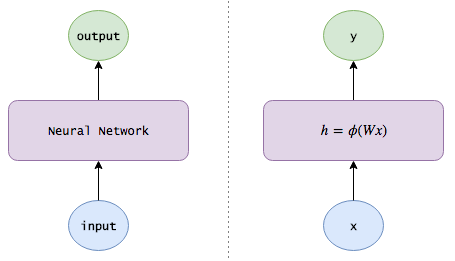
Note: In order to make the symbols more concise, I assume that x and h each contain an additional deviating neuron, and the deviation is set to 1 fixed, which is convenient for learning the bias weight.
Use RNN to remember information
Ignoring the continuous properties of movie images is like the practice of ML 101. If we see a beach scene, we should enhance the beach activity in the next frame: if the person in the image is in the sea, then the image may be marked as "swim"; if the person in the image is closed With the eyes lying on the beach, this image may be marked as "sunbathing". If we can remember that Bob had just arrived at a supermarket, then even without any special supermarket features, Bob's image of a piece of bacon might be labeled as "shopping" rather than "cooking."
Therefore, we want our model to be able to track the various states of the world:
After each image is detected, the model outputs a label and the model's knowledge of the world is updated. For example, the model may learn to autonomously discover and track relevant information, such as location information (where is the scene occurring at home or on the beach?), time (if the scene contains an image of the moon, the model should remember the scene) Occurs at night) and movie progress (is this image the first frame or the 100th frame?). Importantly, just as neurons can automatically discover hidden images (such as edges, graphics, faces, etc.), our models themselves can automatically find useful information.
When you enter a new image into the model, the model should combine the information it collects to accomplish the task better.
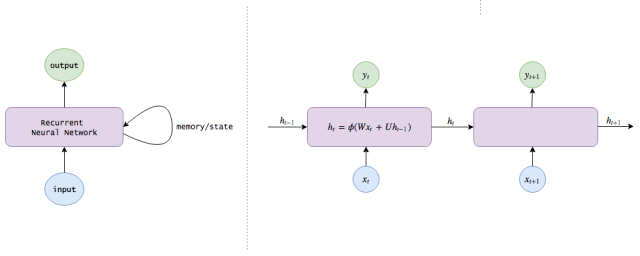
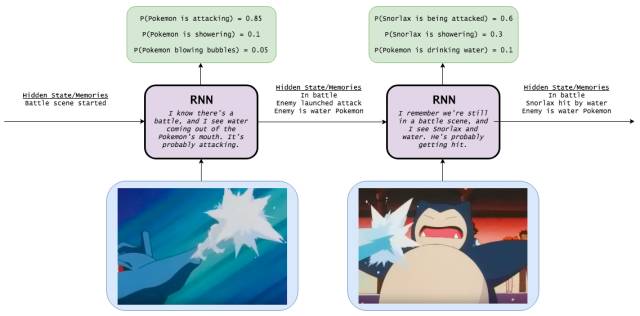
This is the Recurrent Neural Network (RNN), which not only performs simple image input and event output behavior, but also maintains a memory of the world (weighting different information) to help improve its classification function.
Mathematical expression
Next, let's add the concept of internal knowledge to the equation, which we can think of as memories or information that have long been preserved by neural networks.
Very simple: We know that the hidden layers of the neural network have already encoded useful information about the input, so why not use these hidden layers as memories? This idea led us to the following RNN equation:
Ht=φ(Wxt+Uht−1)
Yt=Vht
Note: The implicit state calculated at time t (ht is our internal knowledge) will be fed back to the neural network in the next time step. (In addition, I will use the concepts of hidden state, knowledge, memory and cognition in this article to describe ht)
Leverage LSTM for longer memory
Let us think about how our model updates its understanding of the world. So far, we have not imposed any restrictions on its update process, so the process of understanding the update may be very confusing: in a certain frame, the model may think that the character is in the US; the next frame, when it observes When people eat sushi, they think they are in Japan; in the next frame, when they observe polar bears, they think they are on Hydra island. It is also possible that the vast amount of information collected by the model indicates that Alice is an investment analyst, but she was determined to be a professional killer when she saw her cooking.
This confusion means that information changes and disappears quickly, and it is difficult for models to preserve long-term memory. Therefore, we hope that neural networks can learn how to update their own understanding (that is, scenes without Bob should not change all information related to Bob, and scenes with Alice should focus on collecting information about her), so that neural networks It is possible to update its understanding of the world relatively slowly.
Here's how we do it.
Add a forgetting mechanism. For example, if a scene ends, the model should forget the location and time of the current scene and reset any information related to the scene; however, if a character dies in the scene, the model should continue to remember The fact that the character died. Therefore, we want the model to learn an independent forgetting/memory mechanism: when new inputs are received, the model needs to know which ones should be retained and which ones should be abandoned.
Add a save mechanism. When the model sees a new image, it needs to learn whether all the information about the image is worth using and whether it is worth saving. Maybe your mom sent you an article about the Kardashian family, but who cares?
So when new input is received, the model first forgets all long-term information that it thinks it is no longer needed. Then, learn which parts of the new input information have value in use and save them to long-term memory.
Focus long-term memory as working memory. Finally, the model needs to learn which part of the long-term memory can work immediately. For example, Bob's age may be a useful piece of information that needs to be stored in long-term memory (children are more likely to crawl, adults are more likely to work), but if Bob does not appear in the current scene, then this information is May be irrelevant information. Therefore, the model does not always use all of the long-term memory, it only needs to learn which part of the memory should be focused on.
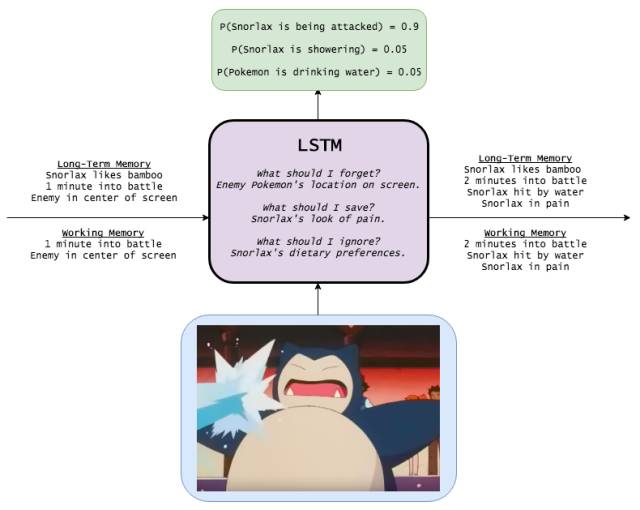
This is the long and short term memory network. The way RNN rewrites memory in each time step can be said to be quite disordered, and LSTM rewrites its own memory in a more precise way: by using a specific learning mechanism to determine which information needs to be remembered, which information needs to be updated, and what information Need special attention. This helps the LSTM to track information over the long term.
Mathematical expression
Let us use mathematical expressions to describe the addition mechanism of LSTM.
At time t, we receive a new input xt. We also pass the long-term memory and working memory from the first two time steps ltmt−1 and wmt−1 (both are n-length vectors) to the current time step for updating.
We deal with long-term memory first. First, we need to know which long-term memories need to continue to remember, and we need to know which long-term memories need to be discarded. Therefore, we use the new input and working memory to learn the n-digit memory gates between 0 and 1, each memory gate determines the extent to which a long-term memory element needs to be retained. (1 means save, 0 means complete forget).
We can use a small neural network to learn this time gate:
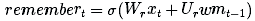
(Note that it is similar to the previous network equation; this is just a shallow neural network. In addition, we use the sigmoid activation function because the number we need is between 0 and 1.)
Next, we need to calculate the information that can be learned from xt, that is, the candidate memory for long-term memory:
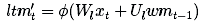
φ is an activation function and is usually chosen as tanh. Before adding candidate memory to long-term memory, we want to learn which part of the candidate memory is worth using and saving:
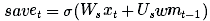
(Imagine what happens when you read the web. When the new news may contain information about Hillary, if the information comes from the Breitbart website, then you should ignore it.)
Let us now combine all these steps. After forgetting the memory we think is no longer needed and saving the useful part of the input, we get the updated long-term memory:
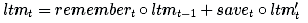
Where ∘ denotes the multiplication of the element-wise element.
Next, let's update the working memory. We want to learn how to focus our long-term memory on information that works immediately. (In other words, we want to learn what data needs to be transferred from an external hard drive to a notebook for work). So here we take a look at the focus/attention vector:
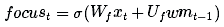
Our working memory is:
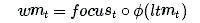
In other words, we pay attention to the element whose vector is 1 and ignore the element whose attention vector is 0.
We are done! I hope that you will also record these steps in your long-term memory.
In summary, a normal RNN uses only one equation to update its hidden state/memory:
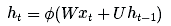
LSTM uses several equations:
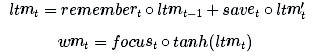
Each of these memory/note sub-mechanisms is just a mini brain of its own:
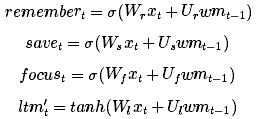
(Note: I use terminology and variable names differently than in regular articles. The following are standard names, which I will use alternately from here:
Long-term memory ltmt is often referred to as the cell state, expressed as ct.
The working memory wmt is usually called the hidden state and is expressed as ht. It is similar to the hidden state in ordinary RNN
The memory vector remembert is often referred to as a memory gate (although 1 in the memory gate still means to retain memory, 0 still means to forget), expressed as ft.
The save vector savet is often referred to as an input gate (because it determines the extent to which the input information needs to be saved to the cell state), expressed as it.
The focus vector focust is often referred to as the output gate, denoted ot. )
Snorlax
At the time of writing this article, I could have caught a hundred Pidgey! Cartoon image of Pidgey below.
Neural Networks
Recurrent neural network
Long and short term memory network
Learn how to code
Let's look at an example of how several LSTMs work. Following the example of Andrej Karpathy, I will use the character-level LSTM model. I enter a character sequence into the model and train it to predict the next character in the sequence.
Although this approach seems a bit naive, the character-level model is really useful, even beyond the text model. E.g:
Imagine an auto-fill coding plugin (code autocompleter) that allows you to encode on your phone. LSTM (theoretically) can track the return type of the method you are currently using, and can make better suggestions for the variables that should be returned; it can also tell you if you are guilty by returning the error type without compiling error.
Natural language processing applications such as machine translation often have difficulty dealing with rare terms. How do you translate a word you have never seen before? Or how to convert adjectives into adverbs? Even if you know the meaning of a tweet, how do you generate a new topic tag to make it easier for others to capture relevant information? The character model can imagine new terms out of thin air, another area where you can implement interesting applications.
First I started an EC2 p2.xlarge Spot instance and trained a Layer 3 LSTM on the Apache Commons Lang codebase. This is a program that the LSTM generates after a few hours.

Although the code is certainly not perfect, it is better than many data scientists I know. We can see that LSTM has learned a lot of interesting (and correct!) coding behavior:
It knows how to construct categories: first the certificate, then the package and input, then the comments and category definitions, and finally the variables and methods. Similarly, it knows how to create a method: the correct instruction followed by the decorator (first description, then @param, then @return, etc.), correctly placed the decorator, the return value is not empty, the method ends with a suitable return statement. Crucially, this behavior runs through long strings of code!
It also tracks the number of subroutines and nesting levels: the indentation of the statement is always correct, and the loop loop structure is always closed.
It even knows how to generate tests.
How is the model done? Let us observe a few hidden states.
This is a neuron that seems to be used to track code indentation (when the model reads a character as input, the state of the code determines the color of the character, ie when the model tries to generate the next character; the red cell is negated , blue cell is affirmative):

This is a neuron that counts the number of spaces between tabs:

This is a distinctive 3-layer LSTM that is trained in the TensorFlow code base for you to try:
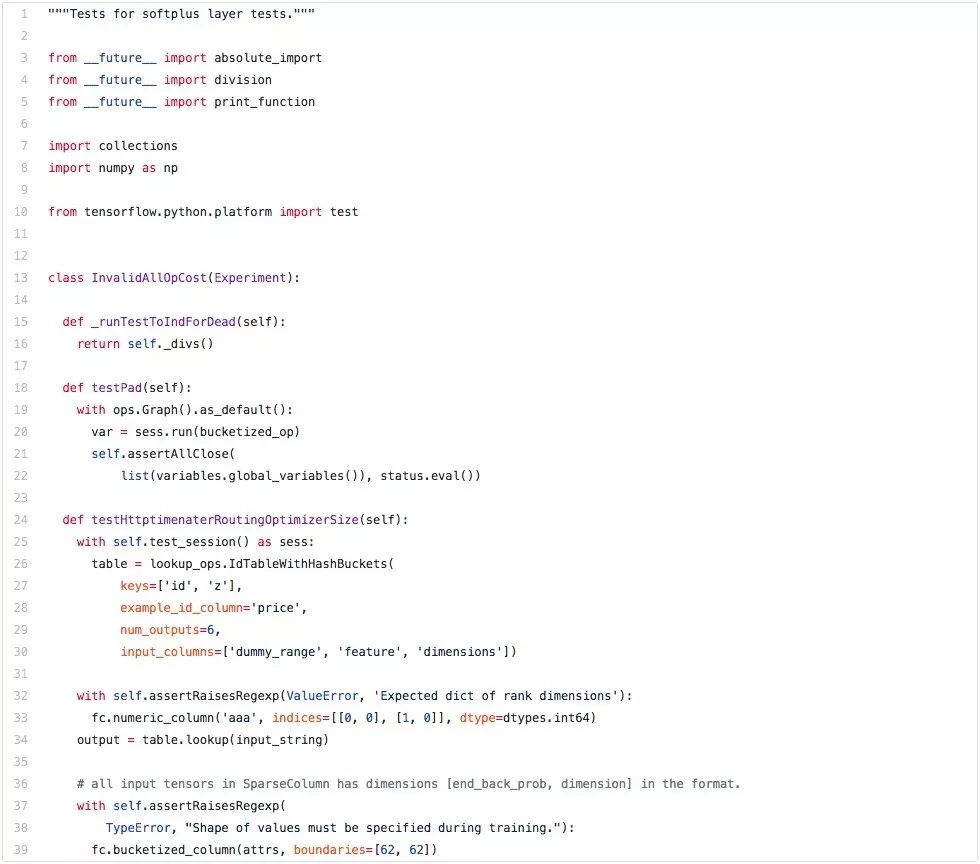
Link: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
If you want to see more examples, you can find many other interesting examples on the web.
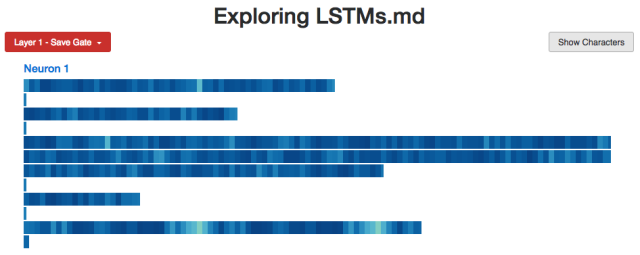
Explore the internal structure of LSTM
Let us study it a bit deeper. We discussed several examples of hidden states in the previous section, but I also want to use the cell state of LSTM and other memory mechanisms. Will they be activated as we expected? Or is there an unexpected pattern?
count
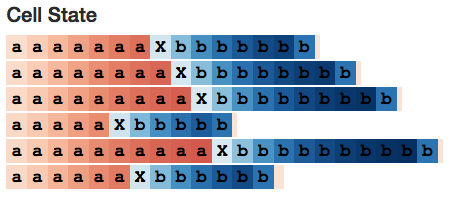
For the sake of research, let's teach LSTM to count. (Remember how LSTM in Java and Python generates the correct indentation!) So I generated this form of sequence

(N "a" followed by a separator X, followed by N "b" characters, where 1 <= N <= 10), and trained a single-layer LSTM with 10 hidden layer neurons.
Unsurprisingly, LSTM has learned very well within its training range - it can be analogized even after out of range. (But when we tried to make it count to 19, it started to make mistakes.)

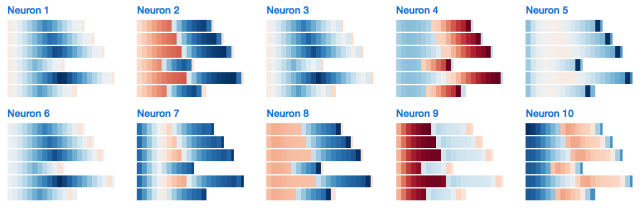
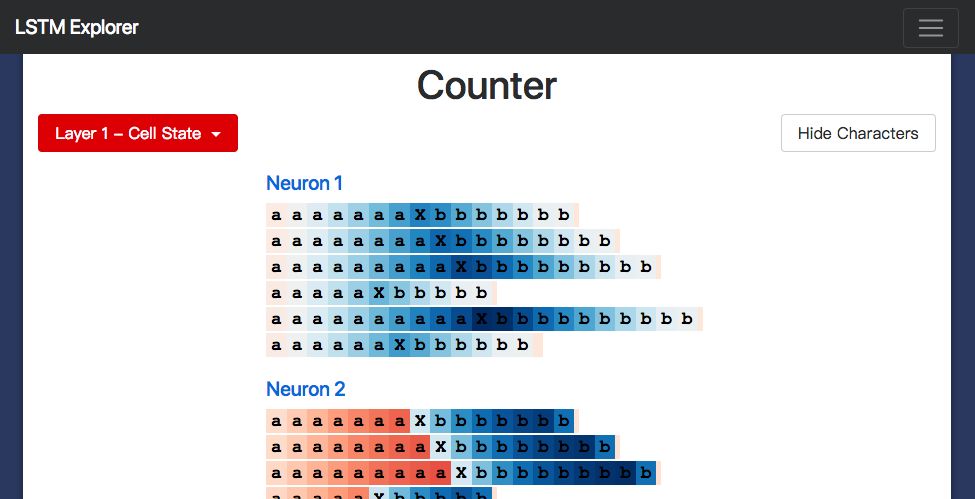
Inside the study model, we expect to find a hidden layer neuron that can calculate the number of a's. We also found one:
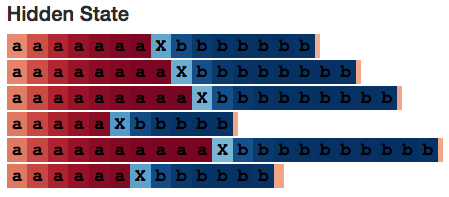
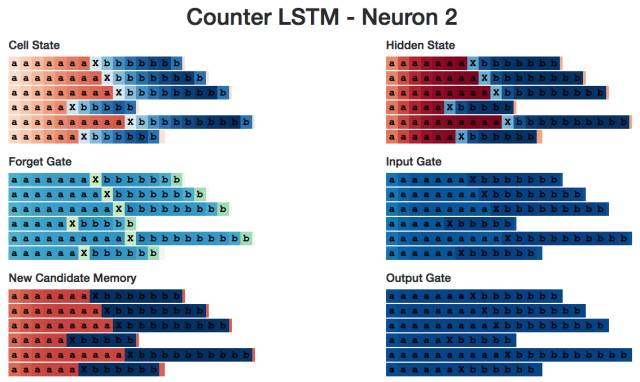
Neuron #2 hidden state
I developed a small web application (http://blog.echen.me/lstm-explorer) using LSTM, and the Neuron #2 count seems to be the total number of a's and b's it can see. (Remember to color the Cell based on the activation state of the neuron, and the color varies from dark red [-1] to dark blue [+1].)
What about Cell status? Its performance is similar:
Neuron #2 Cell Status
Interestingly, working memory looks like a "clearer" long-term memory. Is this phenomenon in the whole?
Does exist. (This is exactly the same as we expected because the tanh activation function compresses long-term memory while the output gate limits memory.) For example, the following is a quick overview of all 10 cell state nodes. We see a lot of light colored cells, which represent values ​​close to zero.
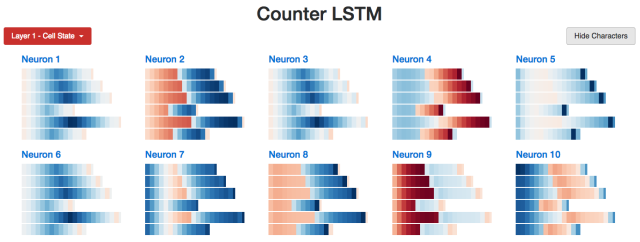
LSTM Cell status statistics
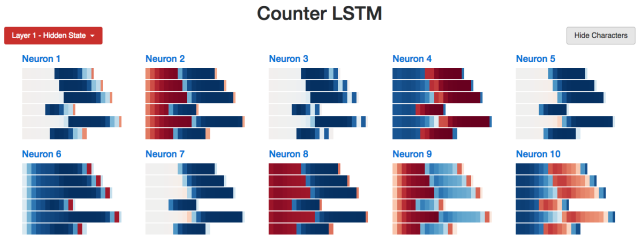
In contrast, the performance of 10 working memory neurons is very concentrated. The neurons 1, 3, 5, 7 are even in a state of zero at the first half of the sequence.
Let us look at neuron #2 again. In the picture are candidate memory and output gates, which are relatively stable in each half of the sequence—it seems that every step of the neuron calculation is a += 1 or b += 1.
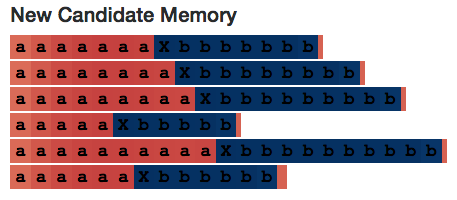

Input gate
Finally, this is an overview of the interior of all neurons 2.
If you want to study different counting neurons, you can use the visualizer provided here.
Link: http://blog.echen.me/lstm-explorer/#/network?file=counter
Note: This is by no means the only way to count LSTM learning. I have used quite a few anthropomorphic techniques in this article. In my opinion, observing the behavior of neural networks is very interesting and helps to build better models. After all, many of the ideas in neural networks are simulations of the human brain. If we can observe behavior we did not expect, Maybe you can design a more effective learning mechanism.
Count von Count
Let's look at a slightly more complicated counter. This time I generated a sequence of this form:

(N a's randomly mixed with a few X's, then add a separator Y, followed by N b's). LSTM still needs to calculate the number of a's, but this time it needs to ignore X's.
This is the complete LSTM (http://blog.echen.me/lstm-explorer/#/network?file=selective_counter). We expect to see a counting neuron, but when the neuron observes X, the input gate is zero. This is indeed the case!

The figure above shows the cell status of Neuron 20. This state is incremented until the delimiter Y is read, and then reduced to the end of the sequence - just as the num_bs_left_to_print variable is calculated, the variable is incremented when a's is read, and decreased when b's is read).
If you look at its input gate, it does ignore X's:
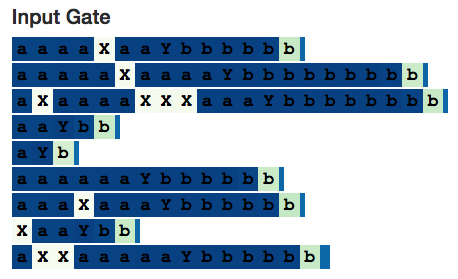
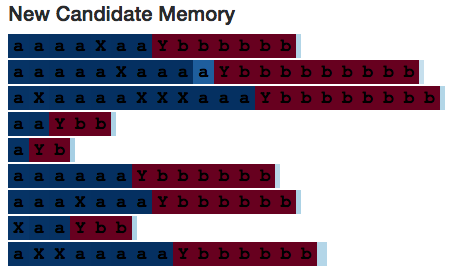
Interestingly, candidate memory is fully activated when reading unrelated X's - this indicates the need to set the input gate. (However, if the input gate is not part of the model structure, then the neural network is likely to learn how to ignore X's by other means, at least in the simple example of the present.)
Let's take a look at Neuron 10.

This neuron is interesting because it only activates when the separator "Y" is read - but it still successfully encodes the number of a's in the sequence. (Maybe it's hard to see from the picture, but when the number of Y's and a's in the sequence is the same, the values ​​of all cell states are either identical, or the error between them is no more than 0.1%. You can see that a's Less Y's are lighter than other a's Y's.) Maybe some other neurons see it when the neuron 10 is lazy.

Remember the status
Next, I want to see how LSTM remembers the state. I generated a sequence of this form:
(ie an "A" or "B", followed by 1-10 x's, followed by a separator "Y", ending with a lowercase of the opening character). In this case, the neural network needs to remember whether it is in the "A" state or the "B" state. We expect to find a neuron that is activated when a sequence beginning with "A" is remembered, and a neuron that is activated when a sequence beginning with "B" is remembered. We did find it.
For example, here is an "A" neuron that will be activated when "A" is read, which will be remembered until the last character is generated. Note: The input gate ignores all "x" characters.
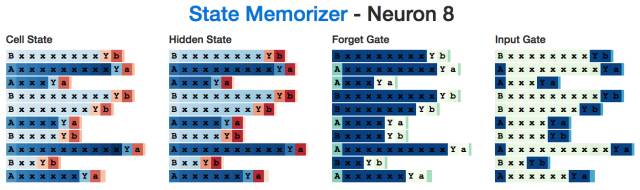
This is a "B" neuron:
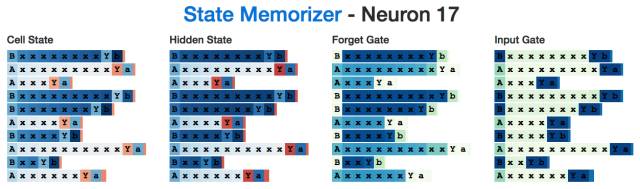
Interestingly, although we don't need to know the A state and the B state until the neural network reads the separator "Y", the hidden state is active throughout the process of reading all intermediate inputs. This seems to be somewhat "inefficient", perhaps because neurons are still doing some other tasks while calculating the number of x's.
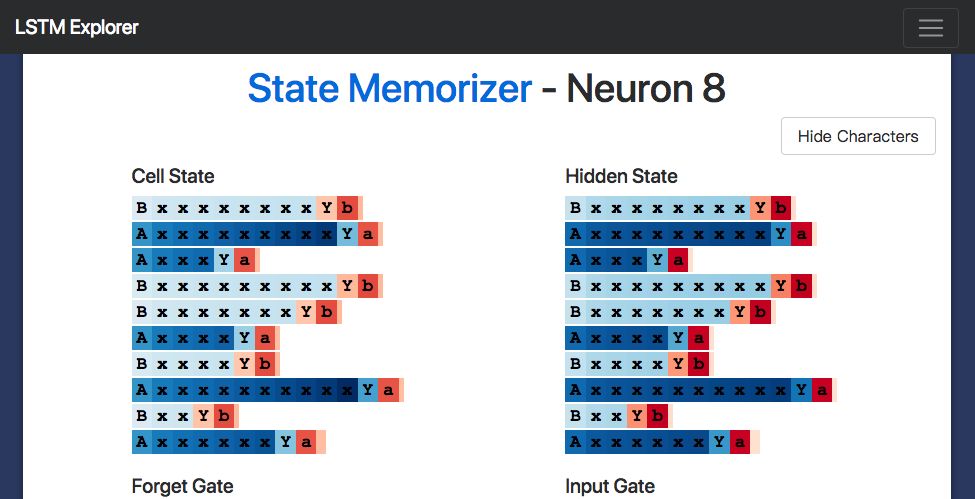
Copy task
Finally, let's explore how LSTM learns to replicate information. (Java LSTM is able to remember and copy Apache licenses.)
Note: Considering how LSTM works, you know that LSTM is not very good at memorizing large amounts of individual and detailed information. For example, you may notice that the code generated by LSTM has a big drawback, that is, it often uses undefined variables - it is not surprising that LSTM cannot remember which variables have been defined because it is difficult to use a single The cell is used to efficiently encode multi-valued information, such as features. At the same time, LSTM does not have a natural mechanism for concatenating adjacent memories to form related discourses. Memory networks and neural Turing machines are two extensions of neural networks that can help to fix this problem by enhancing memory with external memory controls. Therefore, although LSTM does not replicate very efficiently, it is also interesting to observe them for various attempts.
In order to complete the copy task, I trained a small 2-layer LSTM on the sequence of the following form.

(The first is a 3-character sequence consisting of a's, b's, and c's, with a separator "X" inserted in the middle and the first half of the group in the second half).
I'm not sure what the "replicating neurons" look like, so in order to find the neurons that memorize some of the elements of the initial sequence, I observed their hidden state when the neural network read the separator X. Since the neural network needs to encode the initial sequence, its state should present different patterns depending on the content of the learning.
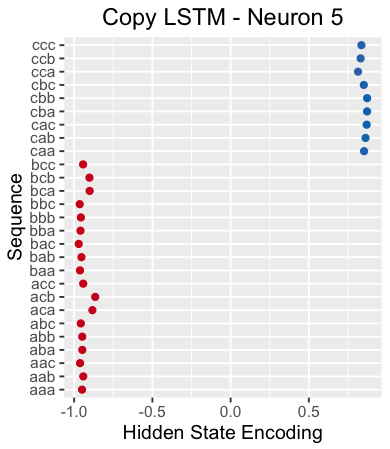
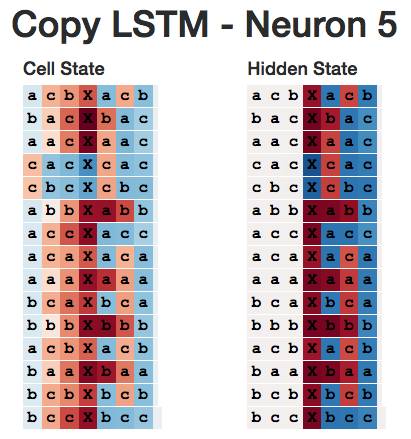
For example, the following figure plots the hidden state of neuron 5 when the neural network reads the separator "X". This neuron clearly distinguishes sequences starting with "c" from different sequences.
As another example, the following figure shows the hidden state of the neuron 20 when the neural network reads the separator "X". The neuron seems to be able to pick out a sequence beginning with "b".
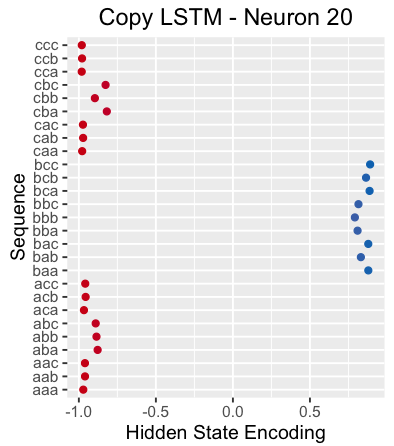
Interestingly, if we look at the cell state of neuron 20, we can see that it captures the entire 3-character sequence almost alone (since the neurons are one-dimensional, this is not easy!):
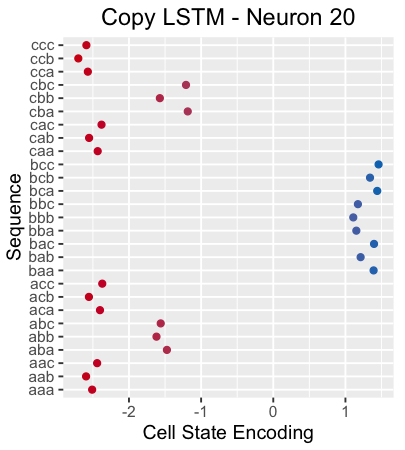
This is the cell state and the hidden state of the neuron 20 throughout the sequence. Note: Its hidden state is turned off throughout the initial sequence (this may be expected, as it is only necessary to passively retain the memory of the neuron at a certain point).
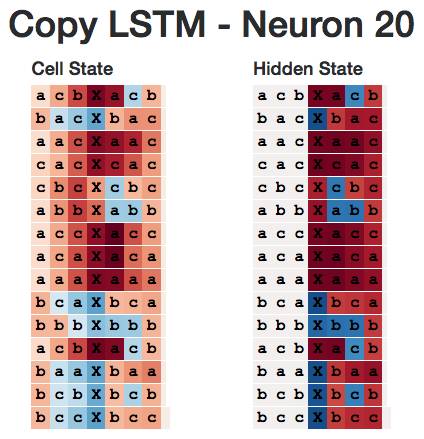
However, if we look more carefully, we will find that the next character is "b" and the neuron will be activated. Therefore, the neuron is not a "b" neuron that starts with "b", but a neuron whose next character is "b".
In my opinion, this pattern applies to the entire neural network - all neurons seem to be predicting the next character, not the characters in a particular location. For example, neuron 5 appears to be a neuron that predicts that the next character is 'c'.
I'm not sure if this is the default behavior that LSTM learns when copying information, and is not sure if there are other replication mechanisms.

State and door
In order to really explore and understand the different states and gates in LSTM, let's repeat before
State and hidden state (memory) cell.
We originally described the cell state as long-term memory, and the hidden state as a way to take out and focus on these memories when needed.
Therefore, when a segment of memory is currently irrelevant, we suspect that the hidden state will be turned off - this is exactly what the sequence replicates.
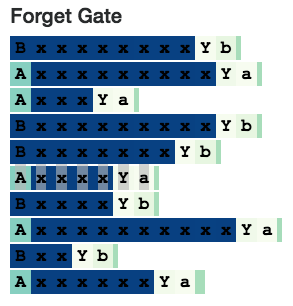
Forgotten door
The Forgotten Gate discards the information about the cell state (0 for complete forgetting and 1 for complete remembering), so we suspect that the Forgotten Gate will be fully activated when it needs to remember exactly what it is, and will be turned off when the remembered information is no longer needed. .
We think this "A" memory neuron uses the same principle: when the neuron reads x's, the memory gate is fully activated to remember that this is an "A" state when it is ready to generate the last "a" "When the memory door is closed.
Input door (save door)
We describe the role of the input gate (which I call "save gate" in principle) to decide whether to save information from a new input. Therefore, it automatically closes when it recognizes useless information.
This is what this option counts for neurons: it counts the number of a's and b's, but ignores the unrelated x's.
Surprisingly, we did not explicitly specify how the input (save), forget (memory), and output (note) doors work in the LSTM equation. The neural network itself learned the best way to work.
Extended reading
Let us recapitulate how to know LSTM alone.
First of all, many of the problems we have to solve are to some extent continuous or temporary, so we should integrate the knowledge we have learned into our models. But we know that the hidden layer of the neural network can encode useful information. So why not use these hidden layers as memories and pass them from one time step to the next? So we got the RNN.
From our own behavior we can know that we can't track information as we like; but when we read new articles about policy, we don't immediately believe that it writes and incorporates it into our understanding of the world. We will selectively decide which information needs to be saved, which information needs to be discarded, and what information is needed to make the decision the next time we read the news. So we want to learn how to collect, update, and use information – why not learn these things without their own mini-neural network? So we get the LSTM.
Now that we've looked at the whole process, we can make the model adjustments ourselves.
For example, you might think that using LSTM to distinguish between long-term memory and short-term memory is meaningless—why not directly build an LSTM? Or, you may also find that separate memory gates and save gates are somewhat redundant—any forgotten information should be replaced by new information, and vice versa. This will lead to another popular LSTM variable, the GRU.
Or maybe you think we shouldn't rely solely on working memory when deciding what information to remember, save, and pay attention to – why not use long-term memory? In this way, you will find Peephole LSTMs.
Revival neural network
Finally, let's look at an example. This example is a 2-layer LSTM trained with President Trump's tweets. Although this data set is small, it is enough to learn many patterns. For example, here's a neuron that tracks the location of a tweet in the topic tag, URL, and @mentions:

Here's a correct noun detector (note: it's not just activated when you encounter an uppercase word):
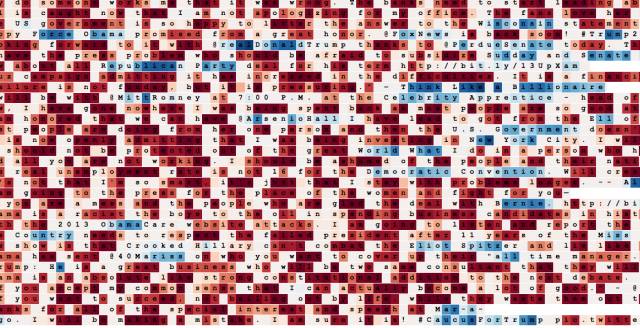
This is a detector for "auxiliary verb + 'to be'" (including "will be", "I've always been", "has never been").

This is a reference determinator:

There is even a MSGA and uppercase neurons:

This is the relevant statement generated by LSTM (well, only one of them is a real tweet; guess which one is really tweet!):
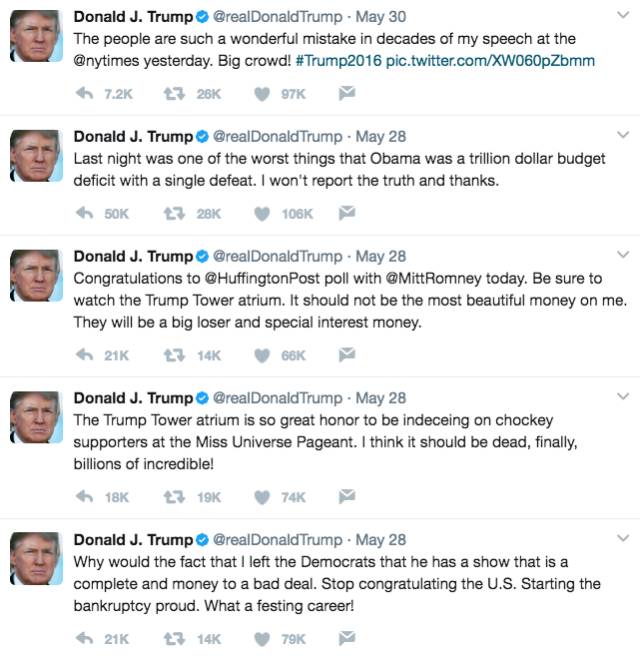

Unfortunately, LSTM only learned how to be crazy like a madman.
to sum up
To sum up, this is what you learned:
This is what you should store in memory:
Shenzhen Guan Chen Electronics Co., Ltd. is a High-tech enterprise that integrates R&D, design, manufacture of computer peripheral products.The products include Thunderbolt Docking Station,USB Docking Station,USB Hubs,USB Adapter, Thunderbolt Cable, SSD Enclosure , HDD Enclosure . Our company adheres to the principle and motto of Being sincere, Responsible, Practical to meet the needs of markets and customers with high quality technology and management. We commit ourselves to new product development and also stress the exploring of international markets.
Our company owns a professional production team and establishes strict quality control standard, so we can provide high quality products and service for customers. We have Grapgic designer,3D Deisnger and Electronic designer to provides professional OEM/ODM service. Our factory covers an area of 1,000-2000 spare meters, which houses 100-200 workers, so our production capacity reaches 50,000 pieces every day.With more than 10 engineers focusing on research and development, our private model attracts much among different markets. Over 100 new designed models are released per year.There are also 3 lean production lines to fullfill small quatity orders production for variety of models.
Our Thunderbolt 3 Docking Station has passed thunderbolt certified by intel and apple.Our product also all can meet with CE, RoHS, UL, FCC and other related certification.And our factory also meets legal environmental standards ensuring your order is delivered. We have a very good reputation at home and abroad. Our products are mainly exported to Europe, USA and Southeast Asia. We provide one-stop-service and promote customers achieve rapidly development. Customer comes First, Quality Ranks First, and Reasonable Price.Guanchen will be your faithful partner from China.
Thunderbolt Ssd Enclosure,40Gbps Thunderbolt 3 Ssd Enclosure,4Tb Thunderbolt 3 Ssd Enclosure,External Ssd Enclosure
Shenzhen GuanChen Electronics Co., Ltd. , https://www.gcneotech.com